Machine Learning on a DMOJ problem: TLE18P1 - Hello, World!
Introduction
TLE 2018-19 P1 - Hello, World! is from an April Fools’ Day contest; it’s not a serious competitive programming problem. If you take a look closely at the sample input, you might figure that the 2 means that there are two test cases and each case is a 28x28 grid of floats. The answers to the cases are 1 and 5 respectively. Now you might think of visualizing these grids:
1
2
3
4
5
6
import matplotlib.pyplot as plt
n = int(input())
for _ in range(n):
a = [list(map(float, input().split())) for i in range(28)]
plt.imshow(a, cmap='binary')
plt.show()
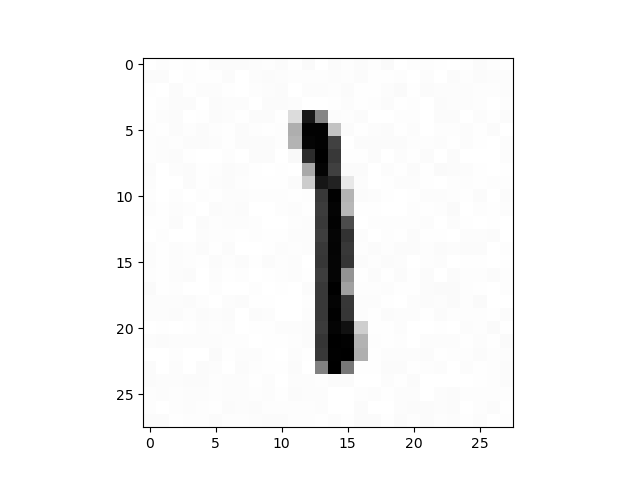 | 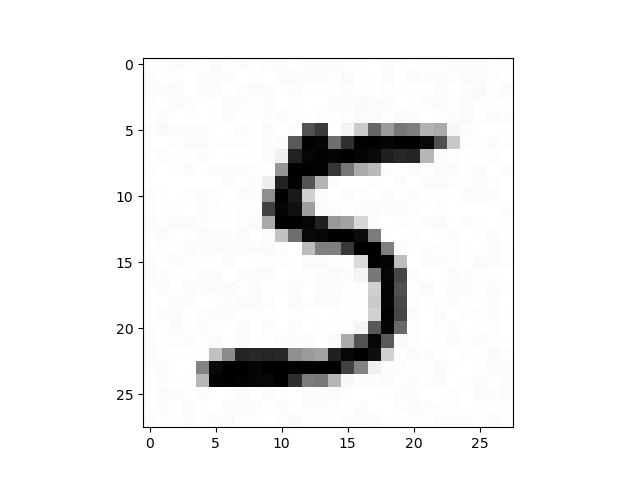 |
Aha! They’re hand-drawn digits! So that’s what the chalkboard image was about.
If you search up “classifying hand drawn digits,” you’ll find that this is a classical machine learning problem. It’s called the “Hello World” of ML.
To solve this problem, we need a neural network to classify the input digits. The problem statement doesn’t say what accuracy is needed, but users commented that we need 95% accuracy to get full marks. If you aren’t familiar with neural networks, 3Blue1Brown does a good job explaining it here.
How to solve it on DMOJ
We can’t import an NN from a DMOJ submission, so we’ll need to write our own neural network. The feed-forward needs to be written by hand, but we don’t have to write code to trains our model. We could train it elsewhere and export the edge weights, but I wanted to test my understanding and implementation skills, so I decided to do it from scratch. Well, not exactly from scratch… I got my training data from MNIST.
After extracting the gzip archives and converting the binary files to plaintext, we can train. My first (working) neural network was something like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
#include <bits/stdc++.h>
#define all(x) (x).begin(), (x).end()
#ifdef LOCAL
template<typename T> void pr(T a){std::cerr<<a<<std::endl;}
template<typename T, typename... Args> void pr(T a, Args... args){std::cerr<<a<<' ',pr(args...);}
#else
template<typename... Args> void pr(Args... args){}
#endif
using namespace std;
using vd = vector<double>;
using vvd = vector<vd>;
using vvvd = vector<vvd>;
mt19937_64 g(0);
double randf(double l, double r){return uniform_real_distribution<double>(l, r)(g);}
struct neural_network{
vvvd edge_weight;
vector<int> layer;
int layercnt;
double const learning_rate = 0.01;
double sigmoid(double x){
return 1/(1 + exp(-x));
}
double derivative_sigmoid(double x){
return sigmoid(x)*(1-sigmoid(x));
}
double cost(vd answer, vd output){
double x = 0;
for(int i = 0; i < size(answer); i++){
x += (answer[i]-output[i])*(answer[i]-output[i]);
}
return x;
}
bool correct(vd answer, vd output){
int i = max_element(all(answer))-answer.begin();
int j = max_element(all(output))-output.begin();
return i == j;
}
void init(vector<int> _l){
for(auto &i: _l)
i++;
layer = _l;
layercnt = size(layer);
edge_weight.resize(layercnt-1);
for(int i = 0; i < layercnt-1; i++){
edge_weight[i].resize(layer[i]);
for(int j = 0; j < layer[i]; j++){
edge_weight[i][j].resize(layer[i+1]);
for(int k = 0; k < layer[i+1]; k++){
if(!j)
edge_weight[i][j][k] = 1;
else if(!k)
edge_weight[i][j][k] = 0;
else
edge_weight[i][j][k] = randf(-.5, .5);
}
}
}
}
pair<vvd, vvd> run(vector<double> input){
vvd values(layercnt), values_after_sigmoid(layercnt);
input.insert(input.begin(), 1); // bias
for(int i = 0; i < layercnt; i++)
values[i].resize(layer[i]);
assert(size(input) == layer[0]);
values[0] = input;
values_after_sigmoid = values;
for(int i = 0; i < layercnt; i++){
for(int j = 0; j < layer[i]; j++){
if(i == 0) values_after_sigmoid[i][j] = values[i][j]/254;
else values_after_sigmoid[i][j] = sigmoid(values[i][j]);
if(i+1 < layercnt){
for(int k = 0; k < layer[i+1]; k++){
values[i+1][k] += values_after_sigmoid[i][j]*edge_weight[i][j][k];
}
}
}
}
return {values, values_after_sigmoid};
}
void train(vector<pair<vd, vd>> tests){
vvvd gradient;
gradient.resize(layercnt-1);
for(int i = 0; i < layercnt-1; i++){
gradient[i].resize(layer[i]);
for(auto &j: gradient[i]){
j.resize(layer[i+1]);
}
}
for(auto [input, answer]: tests){
auto [values, values_after_sigmoid] = run(input);
input.insert(input.begin(), 1);
answer.insert(answer.begin(), 1);
vvd node_derivatives;
node_derivatives.resize(layercnt);
for(int i = 0; i < layercnt; i++){
node_derivatives[i].resize(layer[i]);
}
for(int j = 0; j < layer[layercnt-1]; j++){
node_derivatives[layercnt-1][j] = 2*(values_after_sigmoid[layercnt-1][j] - answer[j]);
}
for(int i = layercnt-1; i > 0; i--){
for(int k = 0; k < layer[i]; k++){
double d = derivative_sigmoid(values[i][k])*node_derivatives[i][k];
for(int j = 0; j < layer[i-1]; j++){
if(k == 0) continue;
gradient[i-1][j][k] += d*values_after_sigmoid[i-1][j];
node_derivatives[i-1][j] += d*edge_weight[i-1][j][k];
}
}
}
}
int testcnt = size(tests);
for(int i = 0; i < layercnt-1; i++){
for(int j = 0; j < layer[i]; j++){
for(int k = 0; k < layer[i+1]; k++){
if(k == 0) continue;
edge_weight[i][j][k] -= gradient[i][j][k]*learning_rate/testcnt;
}
}
}
}
};
I treated the 0th node in each layer as a dummy source for biases. All edges going into dummy nodes had a weight of 0 except for the one coming from the bias of the previous row, which had a value of 1. I also added a 0th dummy node in the input layer that always had a value of 1, so that it would feed all the biases.
DMOJ’s source code character limit
It took a lot of debugging to get my model to work. I then had to face the 64k character limit on DMOJ. My original neural network needed 223k characters to store its edges. I decided to do a 5x5 convolution and 2x2 max pooling in order to shrink my input layer from 28x28 to 12x12 nodes. My new model only needs 45k characters. Plus, it also takes less time to train.
Another way to get around the character limit is to do data compression.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
vvd convolution(vvd pre, int sz){
int n = size(pre);
vvd cur(n-sz+1, vd(n-sz+1));
for(int i = 0; i < n-sz+1; i++){
for(int j = 0; j < n-sz+1; j++){
for(int x = 0; x < sz; x++){
for(int y = 0; y < sz; y++){
cur[i][j] += pre[i+x][j+y]/sz/sz;
}
}
}
}
return cur;
}
vvd max_pooling(vvd pre, int k){
int n = size(pre);
assert(n%k == 0);
int sz = n/k;
vvd cur(sz, vd(sz));
for(int i = 0; i < sz; i++){
for(int j = 0; j < sz; j++){
for(int x = 0; x < k; x++){
for(int y = 0; y < k; y++){
cur[i][j] = max(cur[i][j], pre[i*k+x][j*k+y]);
}
}
}
}
return cur;
}
vd flatten(vvd pre){
vd cur;
for(auto i: pre){
for(auto j: i){
cur.push_back(j);
}
}
return cur;
}
pair<vd, vd> read_and_convolute(ifstream &in){
vd ans(10);
int x; in>>x;
ans[x] = 1;
vvd cur(28, vd(28));
for(auto &i: cur){
for(auto &j: i){
in>>j;
}
}
cur = convolution(cur, 5);
cur = max_pooling(cur, 2);
return {ans, flatten(cur)};
}
I could now create a random model and export it to a file.
1
2
3
4
5
void create_nn(){
neural_network nn;
nn.init({12*12, 30, 10});
nn.export_edges(1);
}
And I repeatedly improved my model with run():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
void run(){
vector<pair<vd, vd>> train_set, test_set, tmp;
// 60000 in train set
// 10000 in test set
ifstream train_input("mnist_train.txt");
train_input.exceptions(ifstream::failbit | ifstream::badbit);
for(int t = 0; t < 60000; t++){
auto [answer, input] = read_and_convolute(train_input);
train_set.push_back({input, answer});
}
train_input.close();
neural_network nn;
nn.import_edges();
for(int i = 0; i < 20000000; i++){
if(i%100000 == 0){
cerr<<"i "<<i<<endl;
}
int j = randint(0, (int)size(train_set)-1);
tmp = {train_set[j]};
nn.train(tmp);
}
nn.export_edges(1);
}
Each time it finished training, I made a DMOJ submission to see what my accuracy was. I spent about one hour training in total.
It took me a long time to come up with workable parameters. I settled on 0.01 as my learning rate. I tried doing k-fold cross-validation and training in epochs (with the entire test set), but those methods trained slower than my method of randomly picking 20,000,000 images to use.
There’s a lot more I can do to optimize my code, but the asymptotically worst parts, namely the feed-forward and backpropagation, were good enough.
Conclusion
By coding up an NN by hand, I found gaps in my understanding. This exercise got me to think through every step of my algorithm and how I should tweak my constants. There’s still more I’d like to explore. For example, when I initially used ReLU, I struggled to address exploding gradients. Once again, I obviously won’t write scrappy NNs by hand in the future; this was just a exercise. I hope to bring you more fun content in the future. Bye! 👋